|
|
||
|
A Concept Map-Based Knowledge Modeling Approach to Expert Knowledge Sharing* |
Abstract
An important aspect of knowledge management is the implementation of methods to share the idiosyncratic knowledge of expert practitioners within an organization. In order to make such knowledge sharable, it is necessary to have both an effective elicitation method and a useful representation scheme. In this paper we describe the PreSERVe method of knowledge elicitation as it is used with a knowledge representation scheme based upon concept maps [1]. We describe the use of these methods in a case study on the capture and representation of local weather forecasting knowledge.
Keywords:
Knowledge Elicitation, Knowledge Modeling, Knowledge Sharing, Concept Maps, PreSERVe Method
1. Introduction
Mission-critical knowledge resides in the memories of experts and in a relatively small subset of what are often distributed external resources that they use, such as technical reports, manuals, books, online materials, etc. In this paper, we describe an iterative method of eliciting expert knowledge called PreSERVe - Prepare, Scope, Elicit, Render, Verify, that presents a principled way to combine various knowledge elicitation strategies [2, 3].
The PreSERVe method was refined in work at NASA Glenn Research Center [10]. The method supports the elicitation of idiosyncratic expert knowledge, the identification of the most important knowledge-rich resources upon which the expert relies, and the assembly of an incrementally evolving representation of the expert's knowledge and problem-solving processes. This method supports construction of an informal but semantically rich representation of expert knowledge and the simultaneous creation and identification of critical supplementary resources that materially augment the representation.
Parallel work at
the Institute for Human and Machine Cognition (IHMC) (e.g., [9,
10, 11]) has led to the development
of a unique way to represent a domain of knowledge. The structure of what
we term a knowledge model is based upon concept maps [1],
a major methodological tool of Ausubel's Assimilation Theory of meaningful
learning [12]. The representation scheme described here
is different from other less formal ones such as mind maps [4],
knowledge maps [5], and the like, in that it conveys
rich semantic content and also provides an organizing factor for other
resources and media that are added to the knowledge model. Also, PreSERVe
affords a more intuitive way to capture tacit knowledge than is required
by formal schemes such as conceptual graphs [6], KADS
[7] and Ontolingua [8] models. The next
sections of this paper elaborate the PreSERVe method, the structure of
a knowledge model, and a case study from the domain of weather forecasting.
2. Knowledge Modeling at the IHMC
This section presents a discussion of the PreSERVe method and of the Concept Map-based knowledge modeling scheme originated at IHMC. Concept Maps are graphs that are comprised of concepts (defined by Novak as perceived regularities in objects and events) on the nodes and the relationships among the concepts on the arcs. Concept Maps are used to form knowledge models by placing them in a hierarchical organization and appending elaborating media onto the nodes within each map. The entire knowledge model is linked together through a general, subsuming top-level map. The resultant model of expert knowledge contains numerous (i.e., hundreds) of domain concepts, principles, and relations that are elicited from the expert, rendered, and verified using the PreSERVe method.
2.1. The PreSERVe Method
Figure 1 depicts the PreSERVe method. It represents the process flow and the flows of resources that are fashioned into the knowledge model. After the initial preparation phase, the process flows are iterative. Preparation has several aspects including the identification of the expert or experts, the selection of the knowledge domain to be explored (if necessary), and study of the domain by the knowledge engineer(s) who facilitate the process. It is also critical to establish a rapport with the expert as part of this phase.
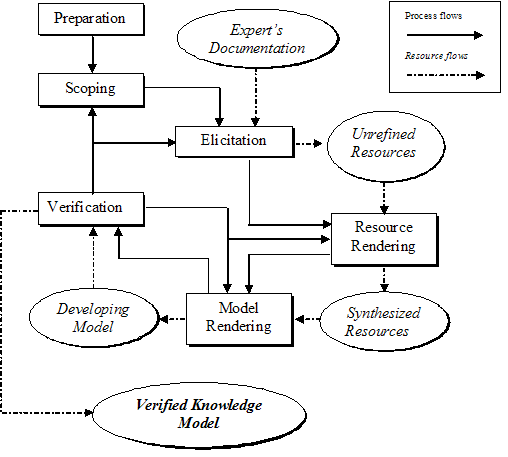
Figure 1. The PreSERVe method of knowledge modeling
The need to maintain and act upon an awareness of the potentially changing scope and direction of the project is one of the major driving forces in defining the PreSERVe method as an iterative process. For this reason, the method represents, as a separate activity, the need to establish and regularly reassess the scope of the endeavor. Experience has shown that a failure to track the scope of a knowledge elicitation project in an ongoing fashion can lead to a haphazard elicitation effort that may go in directions that do not serve the goal of the project, and that may neglect areas that are important to its goals.
The actual elicitation of knowledge can take many forms that can be categorized broadly into those that are direct (in collaboration with the expert) and indirect (through study or inclusion of relevant information sources identified by the expert or knowledge engineer) [13]. Direct methods of knowledge elicitation are chosen from a variety of techniques based upon interviews, analysis of familiar tasks, and so-called contrived (or experiment-like) techniques [3]. The knowledge elicitation process leads to the creation of artifacts (concept maps, interview transcriptions, edited videos of the expert discussing a topic or making a point, etc.) that will be included in the knowledge model.
The rendering process has two parts: The creation or editing of elements that will be included in a knowledge model (resource rendering), and the assembly of these elements into the knowledge model itself (model rendering). These and other pre-existing resources that have been identified in the process (such as selected items from the expert's reference material) are edited into a form that is sufficient to convey what needs to be known about a topic in the model, and that is suitable for presentation in the context of the knowledge model. The complete set of edited resources is characterized as synthesized resources.
The verification process must occur at both a mechanical and conceptual level. Ascertaining that all the components can be found, that the links work (permitting navigation through the media), and that the media display correctly, corresponds to a mechanical verification. A conceptual or semantic verification (by far, the more important of the two types) checks that the factual information is correct and complete, that the best content available at the time is included, that the structure, arrangement and retrieval mechanisms make sense, and that gaps in the elicited knowledge have been filled and significant redundancies avoided.
The PreSERVe method
is iterative since the verification process can lead to the identification
of additional areas that should be explored (a change of scope), under-described
areas in which more comprehensive descriptions should be elicited, areas
where supplementary resources might create a more comprehensive account,
or components that need to be rearranged to make the model more coherent
or logical. Ultimately, a comprehensive, verified model is produced.
2.2 The Structure of a Knowledge Model
The PreSERVe method involves structuring the knowledge model with the concept maps that were elicited to define the scope and vernacular of the domain. Concept maps provide an explicit, concise representation of what the expert knows about a knowledge domain. Knowledge models are ordered in a semi-hierarchical structure with a general, subsuming concept map at the top of the hierarchy and more detailed maps at lower levels.
Figure 2 is a depiction of part of a knowledge model pertaining to weather forecasting on the Gulf Coast of Florida. As can be seen in Figure 2, the concepts within the map are populated with icons that indicate sources of information related to a given concept. An icon is provided for each of the various information sources such as text, graphs, photos, digital audio or video, links to Web pages, etc. The icons appear at the nodes in varying combinations to indicate the media containing information regarding the concept, and links to the concept in other maps or contexts. When the user clicks the icon that represents one of these sources of information, a pop-up menu appears that presents links to the media of the selected type.

Figure 2. A depiction of a knowledge model from the domain of weather forecasting
(click on the image for an larger view)
A special icon representing other concept maps in which a given concept appears is used to indicate links within the model. Clicking that icon presents the user a pop-up menu listing other locations to which the user might navigate. The overall navigational scheme allows the user to start in a model at a given location and view the occurrence of the concept in the other media by clicking the appropriate icon. The user can also examine the other concepts and links in the current map as they relate to the concept under consideration. Since these facilities all occur in the context of a Concept Map set, the user has great navigational flexibility throughout the knowledge model.
Unlike the links in Web-based browsers that convey no semantic content, the connections among concepts in Concept Maps have explicit meanings in two distinct forms [10]. The links between concepts within a single map elaborate the relationships among the concepts in that map. In addition, the linking mechanism that allows a concept in one Concept Map to be linked to the same concept in another, provides the capability to browse more general or more specific elaborations of the concept and to examine the concept in varying contexts. A search capability enables the user of the knowledge model to identify places in the model that contain information on items of interest.
Knowledge models of this sort contain content that is different from the more general information in typical reference material and that is organized quite differently than standard (sequential) textbook knowledge or mainstream hypermedia learning systems. These knowledge models tend to be large and complex (reflecting the complexity of real domains of knowledge) with interwoven themes and rich interconnections of the concepts based on the expert's highly articulated mental model of the domain. As such, these knowledge models contain highly contextualized, domain-specific knowledge that is more directly applicable to specific problem situations than much of the more generic knowledge that typically comprises instructional materials or references.
3. An Example Knowledge Model
The US Navy's meteorology community has a number of interesting knowledge management problems. Theirs is a domain that is characterized by an enormous number of data types and information sources, with new ones continually becoming available. Forecasters work under conditions of significant uncertainty with very high stakes. Weather impacts on training and operational missions are one of the most problematic areas the Navy faces. Furthermore, effects of local conditions can have significant impact on the weather. Knowledge of such local effects is gained by forecasters who have had extensive experience in a particular locale. However, Naval meteorologists' careers typically unfold as a succession of land-based duty stations and assignments to the fleet, with an ongoing need to understand local effects on weather at each new assignment.
A knowledge modeling effort to demonstrate the feasibility of eliciting and representing local meteorological expertise was undertaken at the Naval Training Meteorology and Oceanography Facility (NTMOF) at Pensacola Naval Air Station, Pensacola, FL [14]. Figure 2 presents a depiction of a small but typical part of the knowledge model that was created. The Concept Map labeled "Gulf Coast Region Weather Forecasting" is the top-level map for the model. In front of the top-level map is a more detailed one on the topic of thunderstorms in the Gulf Coast region. Also appearing are other resources that have been accessed, including the text labeled "Thunderstorms," graphics (Annual Frequency of Thunderstorms), satellite imagery, and a digital video of an expert discussing local seasonal variations in thunderstorms.
Knowledge elicitation for the creation of this model primarily utilized concept mapping as a scaffold for structured interviews. A total of 26 Concept Maps on topics such as the local climate, the effects of the Gulf of Mexico on the weather, the various seasonal regimes, fog, thunderstorms, hurricanes, frontal passage, and the local authority's tools and products were created from several iterations of interviews with nine meteorologists. The knowledge model was developed iteratively with review of the Concept Maps after each wave of elicitation, and the assessment of potential resources that could be included in the representation.
Many pre-existing resources such as graphics from the personal collections of the forecasters, links to useful Web sites, etc., were identified and incorporated into the model. Additionally, all the materials from the NTMOF "Local Forecaster's Handbook" were included. Other information such as the Standard Operating Procedures of the installation was attached at appropriate places in the model. A substantial amount of digital video was created from experts' discussions of topics of interest (thunderstorms, hurricanes, fog, etc.) and included. A total of more than 400 information resources were added to the model.
As the project proceeded, verification was performed in two ways. First, the emerging knowledge model was reviewed with the experts to monitor how the model was structured by the Concept Maps. Second, independent verification of the Concept Maps was performed. An independent expert worked through all the elicited Concept Maps, looking for poorly described phenomena and errors. A study of this part of the process showed that experts could evaluate the propositional content in Concept Maps at the rate of approximately 7 propositions per minute. The typical map size was approximately 47 propositions. Approximately 10% of the concepts and linking phrases were changed.
Resource-appended
Concept Maps make useful, highly accessible learning resources. Subsequent
to the creation of the meteorology model described here, several new arrivals
at the installation (journeymen forecasters) used the system as part of
the preparation for the Sub-regional Forecaster qualification examination.
One of the users described the system as a game for browsing and resource
navigation. He recommended that all new arrivals train using the knowledge
model as an adjunct to the traditional learning materials. Another user
of the system made the distinction between "academic" meteorology
and "Operational" meteorology. He stated that the academic part
of learning to forecast is typically quite tedious and uninteresting,
whereas the operational aspects of working the data and making a forecast
were very interesting. He stated further that the current system served
an academic purpose while couching the academic part in a much more operational
setting, thereby making the system both more effective and enjoyable to
use.
4. Summary and Conclusions
This paper contains a report of a knowledge modeling method named PreSERVe - Prepare, Scope, Elicit, Render, Verify - an iterative method of knowledge elicitation, construction and verification that can be used for knowledge modeling. The paper also discusses the use of this method to create a Concept Map-based knowledge model that captured expert knowledge pertaining to local effects on weather forecasting in the Pensacola region of the Gulf Coast. The knowledge model described in this paper was deployed and used by new arrivals at the installation to help them fulfill their first responsibility of qualifying to become Sub-regional forecasters.
Traditionally, knowledge elicitation has been conceived as a sequential process with a pre-defined goal. For example, one elicits knowledge and then does something with it such as building an expert system. In the broader context of modeling expert knowledge, the purposes are often less clear at the outset. It can be difficult to determine the scope of the undertaking in the initial stages of the endeavor for at least two reasons.
1. Such an effort
is typically the first time the expert has attempted to articulate the
nature of his or her expertise.
2. It has been shown that the more significant the expertise, the more
difficult it is for the expert to articulate [13].
The iterative nature of the PreSERVe method addresses these difficulties since expert review of the emerging knowledge model allows the expert to reflect on the representation and identify places that might be improved or corrected. Additionally, the iterative approach to model creation and verification introduces efficiencies into the process since it is easier to assess the increments in the model than to attempt to verify a large, monolithic entity all at once at the end of the knowledge modeling process.
As this and other
knowledge modeling projects have proceeded, it has become evident that
the "real" expertise is not in the documents, texts, or even
the procedural handbooks that the experts use, but rather in bits and
pieces of these, organized to support the heuristic knowledge elicited
to tie them all together. It is just such a construction of knowledge
that the PreSERVe method supports.
As an example, the Navy Gulf Coast Forecasting Handbook discusses a great
many details about fog and moisture advection, but does not mention the
important forecasters' heuristic to look across the airfield to see where
the fog ceiling falls relative to the tree heights to estimate the time
when fog will lift sufficiently so that training flights are permitted.
Such informal knowledge is of significant importance to newer forecasters
who experience pressure to attain competent job performance quickly.
This method is not without drawbacks. Even though it creates efficiencies in the assembly of content-rich knowledge models, such efforts remain quite time and effort intensive. A second issue is model maintenance. If a knowledge model is mainly of an historical nature (such as for institutional memory preservation), the model might remain timely indefinitely. However, the more rapidly the domain changes, the greater the maintenance problem becomes. Knowledge models tend to have some relatively static components and other more dynamically changing ones. A partial solution to the maintenance problem is the attachment of a <volatility> attribute to resource descriptors to foster identification of those resources that potentially change rapidly.
The PreSERVe method is viewed as one among a number of human-centric and machine-centric knowledge management strategies. Knowledge modeling can be employed as one component of strategic knowledge management and sharing. A final benefit of this approach to elicitation and representation of expert knowledge is the breadth of applicability of the final product. In particular, it can be used to support activities such as the preservation of institutional memory, the "recovery" of expertise that might reside in less accessible forms such as archived documents, for performance support, and for other knowledge-intensive pursuits. The content in traditional training or education programs can be augmented or possibly even replaced with well-organized expert practitioner knowledge. The advent of the World Wide Web revolutionizes the use and distribution of such knowledge.
A software suite entitled CMapTools has been created to provide the capability to create knowledge models of the sort described here. The client software allows the Concept Maps themselves to be created and populated with other resources such as text, graphics, video, Web pages, etc. The CmapTools server allows all these resources to reside across multiple machines and to be edited or browsed from any machine that is running the CMapTools client program. Currently, the software may be downloaded for educational and not-for-profit use from the IHMC website. The URL for this Website is http://cmap.coginst.uwf.edu.
With CMapTools, knowledge
models may be shared throughout an organization and may be accessed anytime
and anywhere that permits (and that can be permitted) a connection to
the server where the model resides. Knowledge models can be evolved dynamically.
As an example from the meteorology work described here, forecasters who
have an unusually interesting forecast problem of the day quickly and
easily edit a concept map pertaining to the problem, or add additional
resources or links to helpful on-line data into the resource database.
This activity makes existing and new knowledge available to anyone with
interest in or a need to know about the domain.
Acknowledgements
The example knowledge modeling effort was made possible by the assistance and cooperation of the administrative staff and operational personnel of the Naval Oceanography and Meteorology Training Facility, Pensacola Naval Air Station.
References
[1] J.D. Novak, & D.B. Gowin , Learning how to learn (Ithaca, NY: Cornell University Press, 1984).
[2] J.H. Boose, Knowledge acquisition for knowledge-based systems B.R. Gaines & J.H. Boose. (Eds), (San Diego. Academic Press Ltd, 1986).
[3] R.R. Hoffman, N.R. Shadbolt, A.M. Burton, & G. Klein, Eliciting knowledge from experts: A methodological analysis, Organizational Behavior and Human Decision Processes, 62(2), 1995, 129-158.
[4] C.A. Michelini, Mind Map: A new way to teach patients and staff, Home Healthcare Nurse, 18(5), 318-322.
[5] J.L. Gordon, Creating knowledge maps by exploiting dependent relationships, Knowledge-Based Systems, 13, 2000, 71-79.
[6] J.F. Sowa, Conceptual graphs as a universal knowledge representation, Computers & Mathematics with Applications, 23(2-5), 1992, 75-93.
[7] L. Moreno, R.M. Aquilar, J.D. Pineiro, J.I. Estevez, J.F. Sigut, C. Gonzalez, Using KADS methodology in a simulation assisted knowledge based system: application to hospital management, Expert Systems with Applications, 20, 2001, 235-249.
[8] T. Gruber, A translation approach to portable ontology specifications, Knowledge Acquisition, 5(2), 1993, 199-220.
[9] A.J. Cañas, J.W. Coffey, T. Reichherzer, G. Hill, N. Suri, R. Carff, T. Mitrovich, & D. Eberle, El-Tech: A performance support system with embedded training for electronics technicians. Proc. 11th Florida AI Research Symposium (FLAIRS '98), Sanibel Island, FL, USA, 1998.
[10] J.W. Coffey, Institutional memory preservation at NASA Glenn Research Center. Unpublished technical report, NASA Glenn Research Center, Cleveland, OH, USA, 1999.
[11] K.M. Ford, J.W. Coffey, A.J. Cañas, C.W. Turner, & E.J. Andrews, Diagnosis and explanation by a Nuclear Cardiology Expert System. International Journal of Expert Systems, 9(4), 1996, 499-506.
[12] D.P. Ausubel, Educational psychology: A cognitive view (New York, NY: Holt, Rinehart and Winston, Inc., 1968).
[13] D.A. Waterman, A guide to expert systems (Reading, MA: Addison-Wesley Publishing Company, 1986).
[14] R.R. Hoffman, J.W. Coffey, K.M. Ford, & M.J. Carnot, STORM-LK: A human-centered knowledge model for weather forecasting. Proc. 45th Annual Meeting of the Human Factors and Ergonomics Society, Minneapolis, MN, USA, 2001.
This
paper will be presented at IKS
2002: The IASTED International Conference on Information and Knowledge
Sharing, 2002.